I met Clean Architecture at first hand reading Uncle Bob’s book with the same title, and I immediately fell in love with the simplicity and applicability of his principles. Clean Architecture is all about enforce right policy rules to the way in which your software architecture is organized and more important, making it evolvable, delaying technology decisions as much as possible, as the Uncle Bob himself stated:
The strategy behind that facilitation is to leave as many options open as possible, for as long as possible, Robert C. Martin
Clean Architecture has lots of different interpretations and implementations around. I’ve tried to implement CQRS with Clean in the best way to take advantage of the main concepts of this architectural pattern, making a sample microservice template flexible, maintainable, evolvable, testable, detached from technology and what I think as more important respecting the policy rules, which ensure that dependencies are always lower level than their definitions.
Source Code dependencies must point only inward, towards higher-level policy, Robert C. Martin
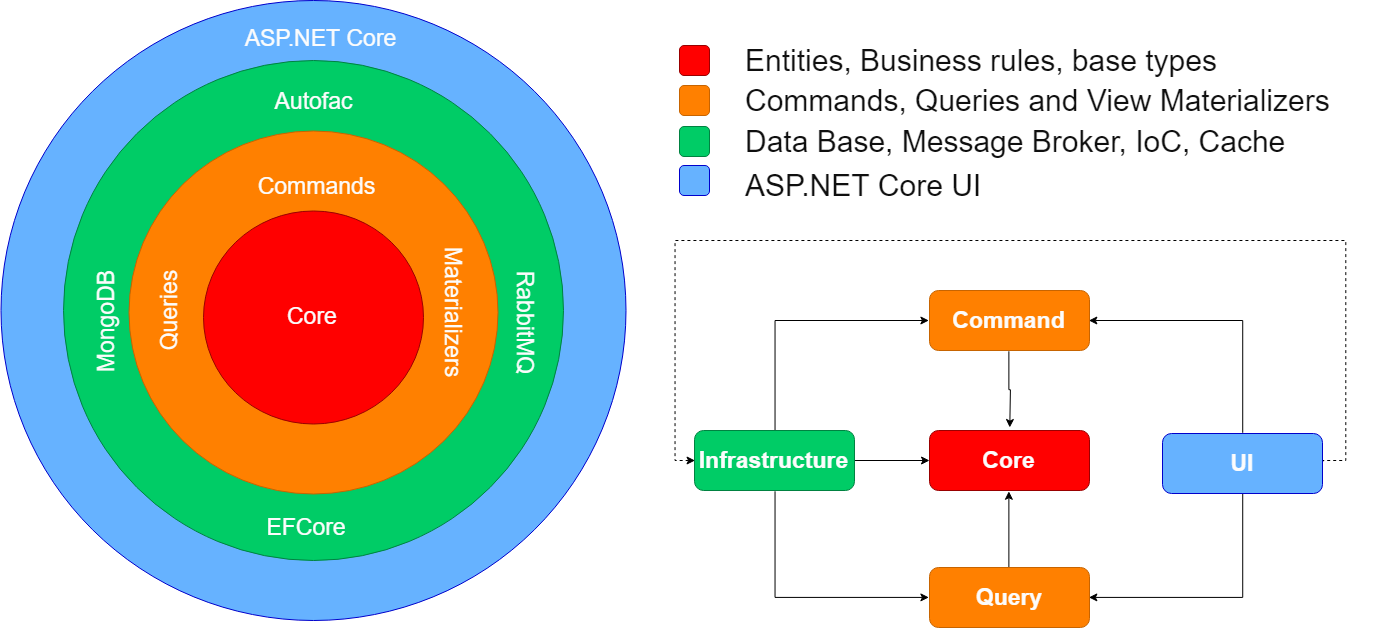
This implementation brings as inner ring what I call Core, where you should implement your business rules, and keep the base of you microservice itself, such as: important interfaces, business entities, base classes, events. You’re going to find that I’m using DDD here, with entities, aggregates, value objects and repository pattern. I’ve seen some implementations calling it Domain, but we shouldn’t restrict this as a pattern or principles names, because what we can have there is more than what the DDD pattern do, is the heart of the application itself. Also, even if CQRS and DDD are likely to be used together, you can implement your business the way you want and take advantage of what is more important, data intensive applications.
The next ring, which many implementations call it Application contains our Use Cases. CQRS has a strict way to implement these Use Cases, we have a stack responsible for dealing directly with your Business Entities, adding, updating or removing, residing inside Command. Those Use Cases that require reading data are inside Query, and the ways to transform business entities to Derived Data format, which is more suitable for reading. Consider both layers Application, they are at the same level, but in different assemblies with different responsibilities.
The Infrastructure is responsible strictly to keep technology. You can find there the implementations of repositories for business entities, message brokers, dependency injection and any other thing that represents a detail for Clean Architecture, mostly framework dependent, external dependencies, and so on.
The outer ring contains a way for users to communicate with our application, the UI. This layer can be anything that allow data input or retrieving. For this implementation I’m using ASP.NET as UI layer.
CQRS
In most scenarios business domains are complex, and they grow even more in complexity over time. Implementing simple queries using the same model became harder and using the same entities to perform them not suitable.
To address this problem a good alternative is CQRS pattern. CQRS is an acronym for Command and Query Responsibility Segregation. As mentioned we have a well-defined segregation between the model you write from the one you read.
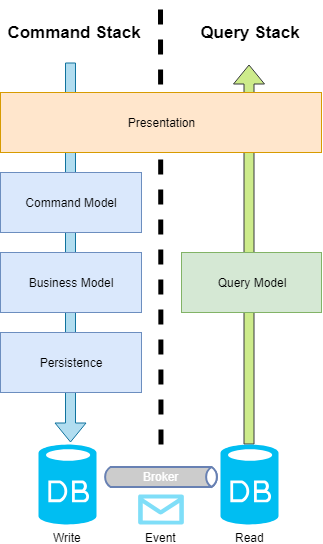
This pattern is an excellent choice to maintain the scalability of your system, given the single responsibility of each stack, you can perform tuning to the stack in which more commonly operations are performed.
For example, if you have a heavy load in the query stack you should implement cache strategies and database replication to balance and drastically improve readings. In other hand, if you have a heavy write load in your system, you could simply turn the command stack from a sync model to an async model to improve it.
Separating queries from commands gives you the chance to work on the scalability aspects of both parts in total isolation, Dino Esposito, Architecting for the Enterprise 2nd edition
This microservice template contains an implementation of CQRS with different databases, which makes even more clear the separation between commands and queries.
Although, CQRS bring complexity to your system, given that you must support messaging brokers and events to guarantee the synchronization between the write database and the read database.
Command Stack
Commands are responsible for performing writes in your system and should be task based.
Each command has its own handler, in which the Use Case is implemented. Every time a command is dispatched and processed if the outcome is successful, an event is published into a message broker with all needed information from your business entity, thereby your query stack can acknowledge changes in the write model and persist it into the read database.
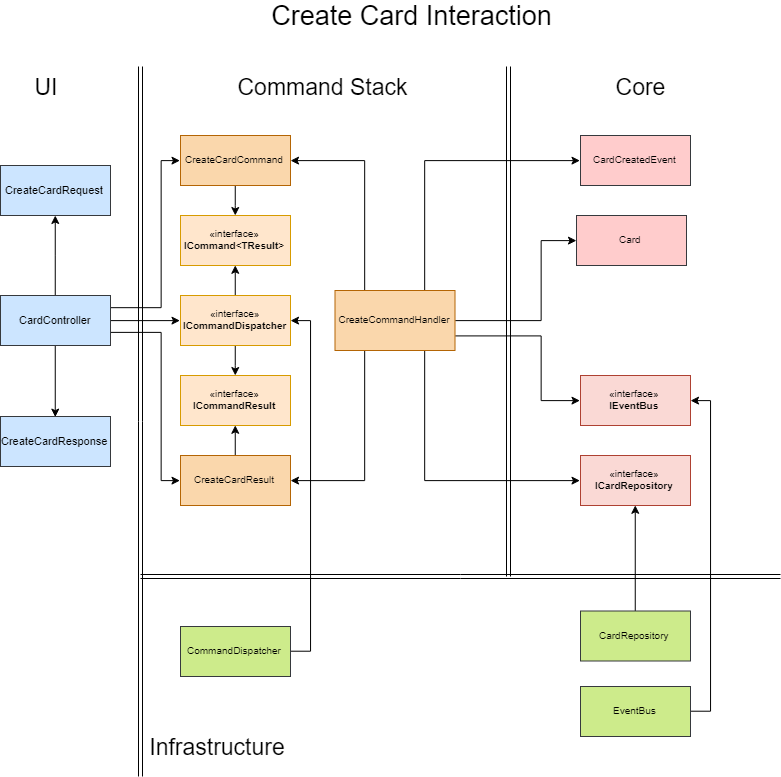
The example above you can see a CreateCardCommand, which is handled by the CreateCardCommandHandler. The handler acts as the Use Case implementation, making the interactions between the command and Card domain entity. The Card is created given the data carried by the command and persisted using the CardWriteOnlyRepository. A CardCreatedEvent is then published to the event bus and a CreateCardCommandResult is returned to the caller.
Every command has a result pair in this implementation, because it’s not using an async model for the command stack. If you go for an async model, you could publish the result or even another event to a message queue to inform other clients.
Query Stack
Having our command stack interacting directly with our business entities and writing data to the write only database leaves our query stack as the one responsible for reading data from the read only database.
The Query stack is a simplified application layer in which data is requested by a Query object, handled by a Query Handler and represented by simple DTOs called QueryModel.
The idea behind the a QueryModel is creating a model with the exact fields for clients of a specific Query, making easy to display data, aggregate information and tuning using indexes and caching.
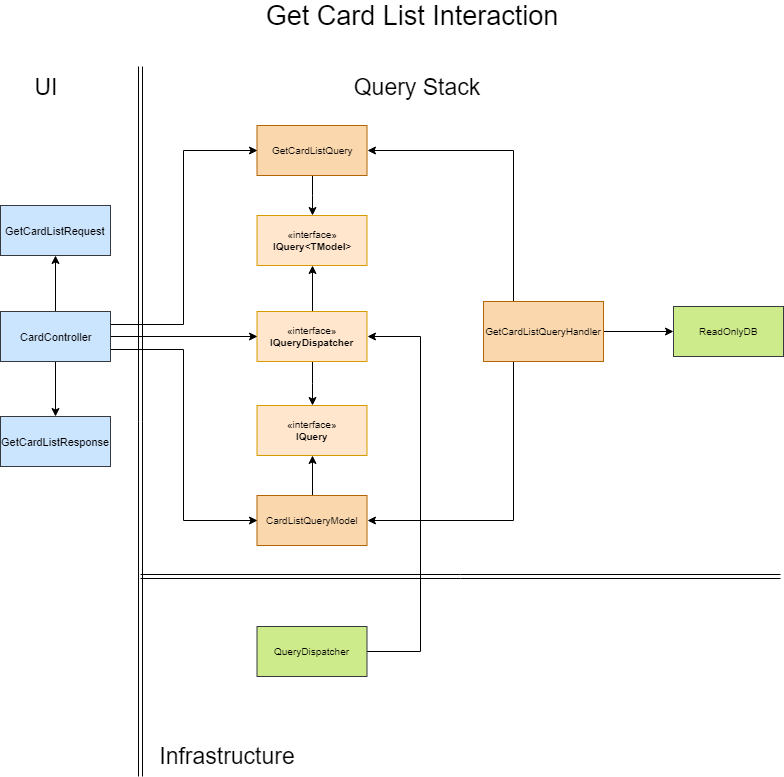
The simple example above contains a representation of a query to retrieve a list of cards. GetCardListQuery contains every filter required to query the database. Thus, the CarListQueryModel is a representation of what the consumer of the query wants to see and the materialization of how we store these representations.
The QueryModel should contain fields and aggregated information in a format similar of Materialized View, well known for data analysis in Datawarehouse.
Show me the code
The source code is hosted on GitHub: https://github.com/fals/cqrs-clean-eventual-consistency
References
Here’s a list of reliable information used to bring this project to life.